
A re-introduction to Kubernetes
A couple years ago I started working with Kubernetes and I simply fell in love with the design, the usability and the power behind such a great product.
My goal with this blog post is to provide a re-introduction to Kubernetes and provide simple reference applications that you can follow along.

Introduction to Kubernetes
Kubernetes is an open-source platform for automating deployment, scaling, and operations of application containers across clusters of hosts, providing container-centric infrastructure.
With Kubernetes, you are able to quickly and efficiently respond to customer demand:
- Deploy your applications quickly and predictably.
- Scale your applications on the fly.
- Seamlessly roll out new features.
- Optimize use of your hardware by using only the resources you need.
Kubernetes is not a traditional, all-inclusive PaaS (Platform as a Service) system. It preserves user choice where it is important:
- Kubernetes does not limit the types of applications supported. It does not dictate application frameworks (e.g., Wildfly), restrict the set of supported language runtimes (e.g., Java, Python, Ruby), cater to only 12-factor applications, nor distinguish “apps” from “services”. Kubernetes aims to support an extremely diverse variety of workloads, including stateless, stateful, and data-processing workloads. If an application can run in a container, it should run great on Kubernetes.
- Kubernetes does not provide middleware (e.g., message buses), data-processing frameworks (e.g., Spark), databases (e.g., mysql), nor cluster storage systems (e.g., Ceph) as built-in services. Such applications run on Kubernetes.
- Kubernetes does not have a click-to-deploy service marketplace.
- Kubernetes is unopinionated in the source-to-image space. It does not deploy source code and does not build your application. Continuous Integration (CI) workflow is an area where different users and projects have their own requirements and preferences, so we support layering CI workflows on Kubernetes but don’t dictate how it should work.
- Kubernetes allows users to choose the logging, monitoring, and alerting systems of their choice.
- Kubernetes does not provide nor mandate a comprehensive application configuration language/system (e.g., jsonnet).
- Kubernetes does not provide nor adopt any comprehensive machine configuration, maintenance, management, or self-healing systems.
Kubernetes Architecture
The following diagram depicts a Kubernetes cluster which consist of worker machines, called Nodes. The Control Plane pictured on the left of the diagram manages the worker nodes and the Pods in the cluster.
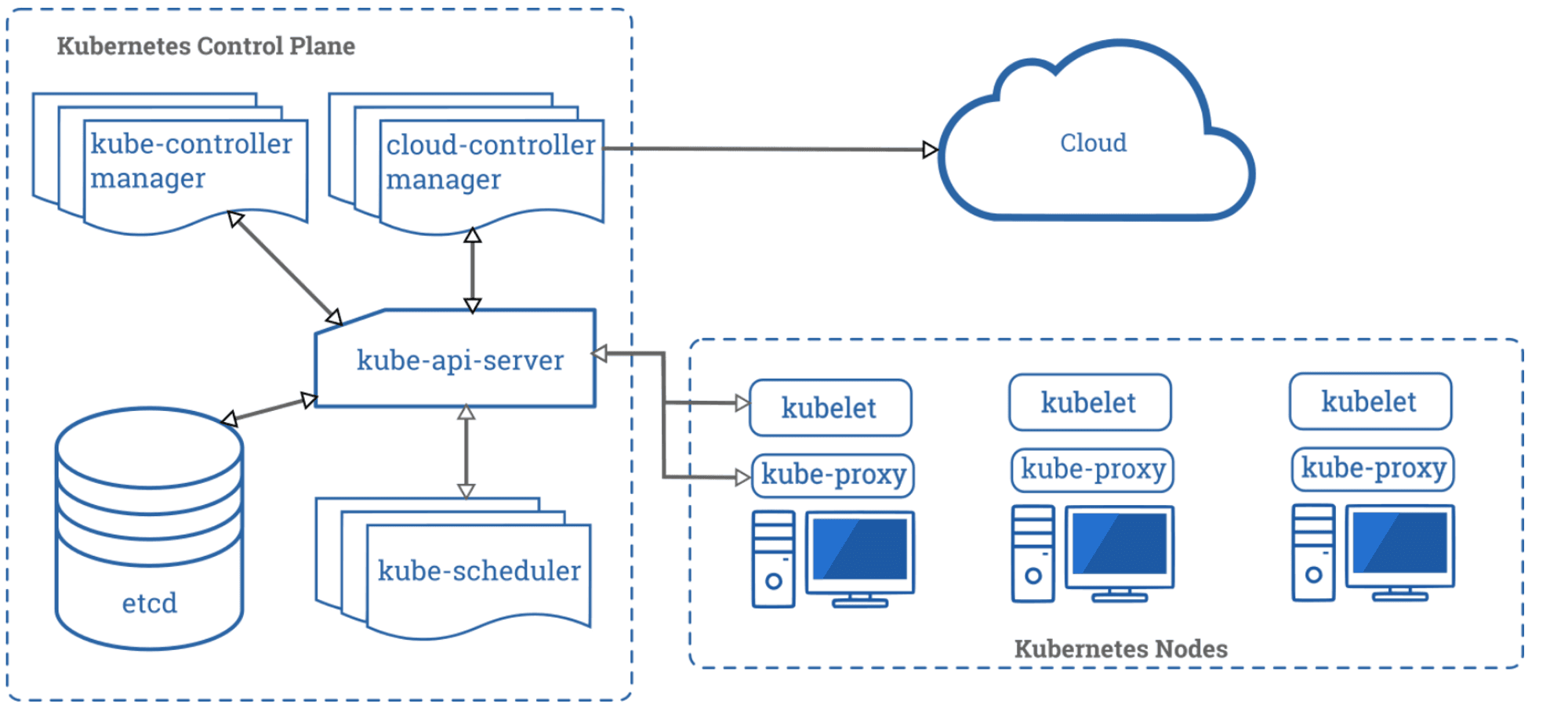
Kubernetes cluster diagram
Kubernetes is composed of different components, each of them playing an important and unique role in the cluster. Below are the most common components and a short description.
Namespaces
Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces.
Namespaces are intended for use in environments with many users spread across multiple teams, or projects. For clusters with a few to tens of users, you should not need to create or think about namespaces at all. Start using namespaces when you need the features they provide:
- Namespaces provide a scope for names. Names of resources need to be unique within a namespace, but not across namespaces.
- Namespaces are a way to divide cluster resources between multiple uses (via resource quota).
- In future versions of Kubernetes, objects in the same namespace will have the same access control policies by default.
It is not necessary to use multiple namespaces just to separate slightly different resources, such as different versions of the same software: use labels to distinguish resources within the same namespace
Pods
A Pod is the basic building block of Kubernetes–the smallest and simplest unit in the Kubernetes object model that you create or deploy. A Pod represents a running process on your cluster.
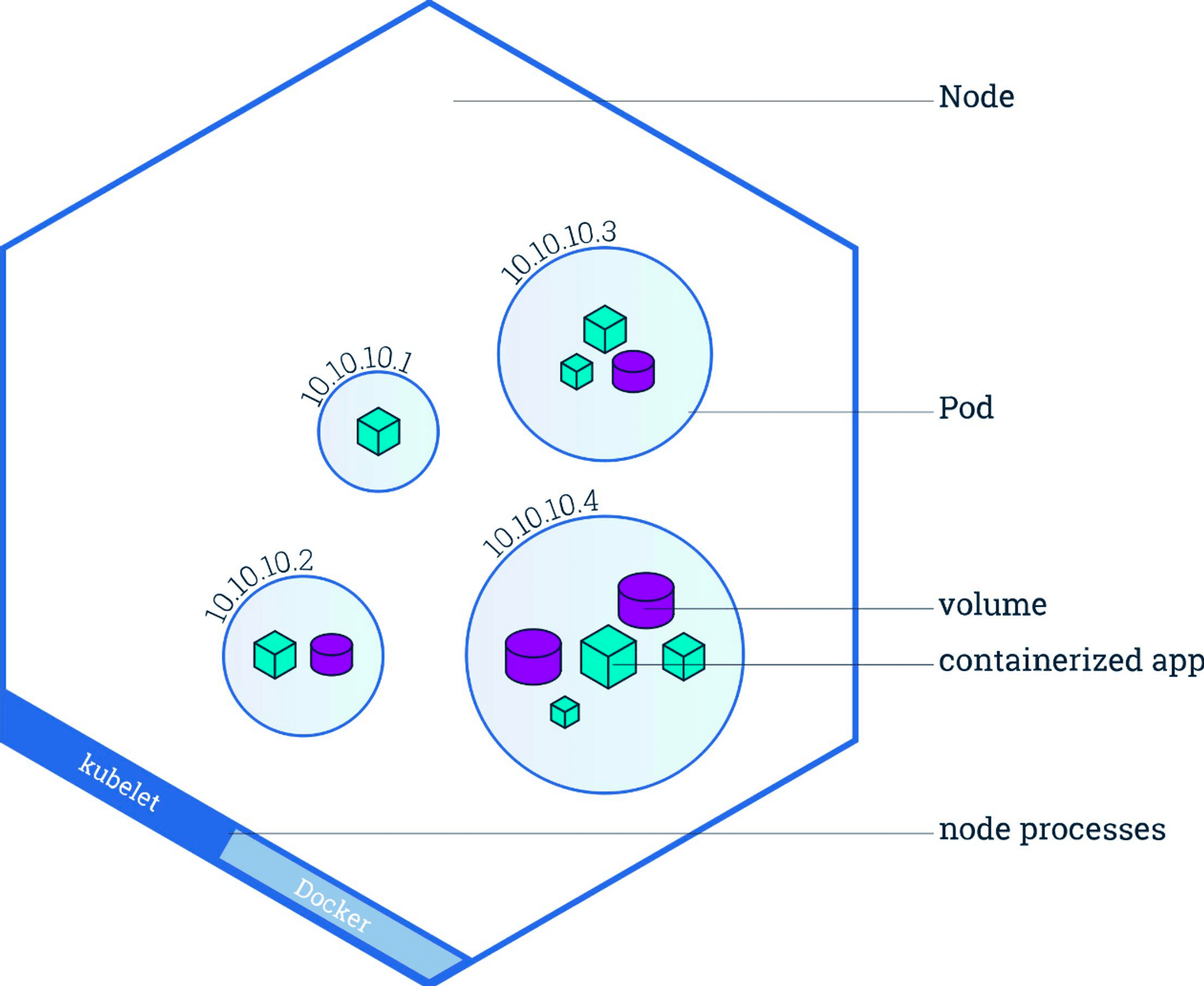
Kubernetes Pod
A Pod encapsulates an application container (or, in some cases, multiple containers), storage resources, a unique network IP, and options that govern how the container(s) should run. A Pod represents a unit of deployment: a single instance of an application in Kubernetes, which might consist of either a single container or a small number of containers that are tightly coupled and that share resources.
Docker is the most common container runtime used in a Kubernetes Pod, but Pods support other container runtimes as well.
Pods are employed a number of ways in a Kubernetes cluster, including:
- Pods that run a single container. The “one-container-per-Pod” model is the most common Kubernetes use case; in this case, you can think of a Pod as a wrapper around a single container, and Kubernetes manages the Pods rather than the containers directly.
- Pods that run multiple containers that need to work together. A Pod might encapsulate an application composed multiple co-located containers that are tightly coupled and need to share resources. These co-located containers might form a single cohesive unit of service–one container serving files from a shared volume to the public, while a separate “sidecar” container refreshes or updates those files. The Pod wraps these containers and storage resources together as a single managable entity.
Deployments
A Deployment provides declarative updates for Pods and Replica Sets (the next-generation Replication Controller). You only need to describe the desired state in a Deployment object, and the Deployment controller will change the actual state to the desired state at a controlled rate for you. You can define Deployments to create new resources, or replace existing ones by new ones.
Kubernetes Cluster with a deployment
A typical use case is:
- Create a Deployment to bring up a Replica Set and Pods.
- Check the status of a Deployment to see if it succeeds or not.
- Later, update that Deployment to recreate the Pods (for example, to use a new image).
- Rollback to an earlier Deployment revision if the current Deployment isn’t stable.
- Pause and resume a Deployment
Services
Kubernetes Pods are mortal. They are born and when they die, they are not resurrected. ReplicationControllers in particular create and destroy Pods dynamically (e.g. when scaling up or down or when doing rolling updates). While each Pod gets its own IP address, even those IP addresses cannot be relied upon to be stable over time. This leads to a problem: if some set of Pods (let’s call them backends) provides functionality to other Pods (let’s call them frontends) inside the Kubernetes cluster, how do those frontends find out and keep track of which backends are in that set?
Enter Services.
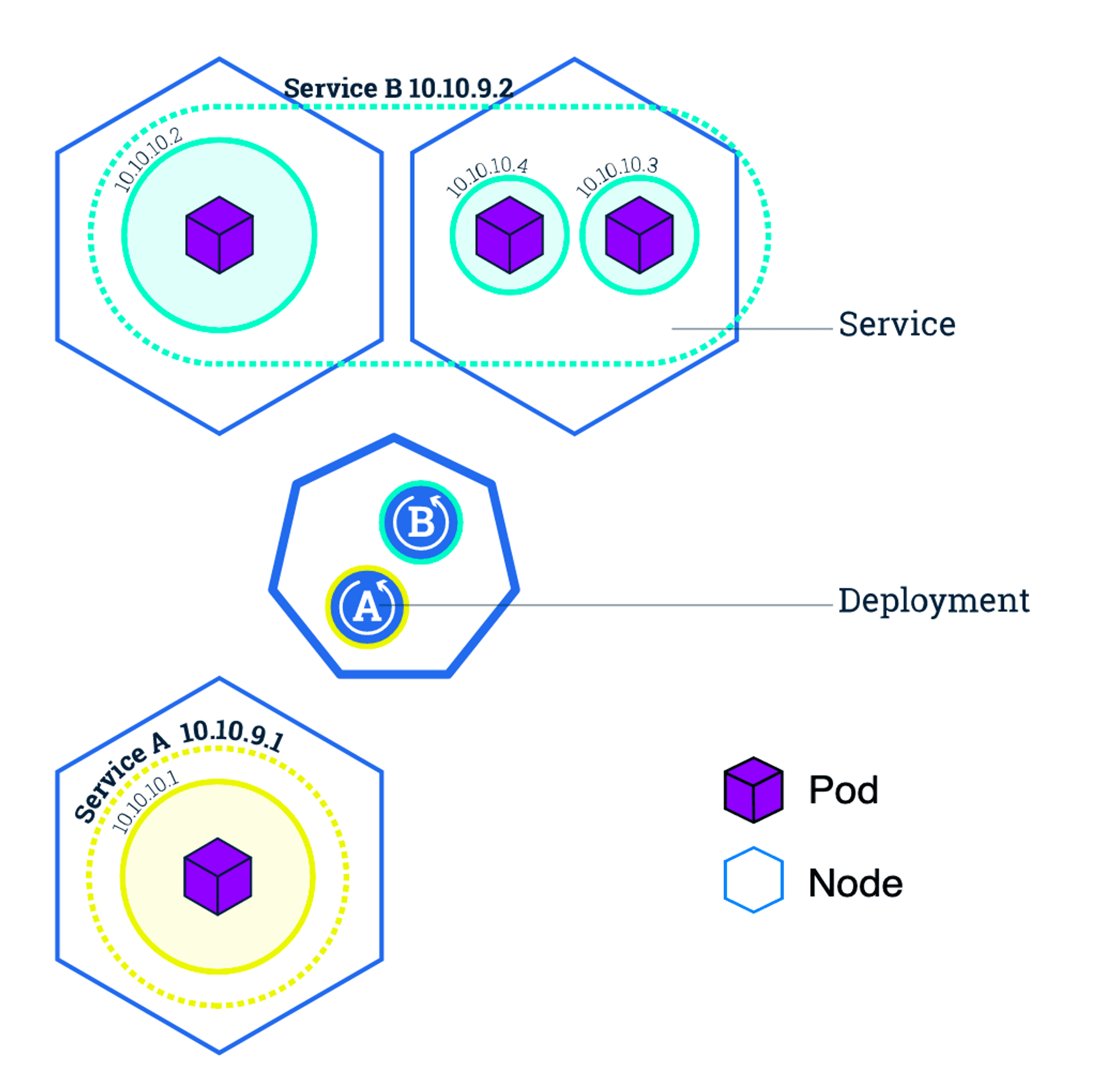
Kubernetes Cluster with Services
A Kubernetes Service is an abstraction which defines a logical set of Pods and a policy by which to access them — sometimes called a micro-service. The set of Pods targeted by a Service is (usually) determined by a Label Selector (see below for why you might want a Service without a selector).
As an example, consider an image-processing backend which is running with 3 replicas. Those replicas are fungible — frontends do not care which backend they use. While the actual Pods that compose the backend set may change, the frontend clients should not need to be aware of that or keep track of the list of backends themselves. The Service abstraction enables this decoupling.
For Kubernetes-native applications, Kubernetes offers a simple Endpoints API that is updated whenever the set of Pods in a Service changes. For non-native applications, Kubernetes offers a virtual-IP-based bridge to Services which redirects to the backend Pods.
Ingress
Typically, services and pods have IPs only routable by the cluster network. All traffic that ends up at an edge router is either dropped or forwarded elsewhere. An Ingress is a collection of rules that allow inbound connections to reach the cluster services. It can be configured to give services externally-reachable urls, load balance traffic, terminate SSL, offer name based virtual hosting etc. Users request ingress by POSTing the Ingress resource to the API server. An Ingress controller is responsible for fulfilling the Ingress, usually with a loadbalancer, though it may also configure your edge router or additional frontends to help handle the traffic in an HA manner.
However, in order for the Ingress resource to work, the cluster must have an Ingress controller running. This is unlike other types of controllers, which typically run as part of the kube-controller-manager binary, and which are typically started automatically as part of cluster creation. You need to choose the ingress controller implementation that is the best fit for your cluster, or implement one. Examples and instructions can be found here.
ConfigMaps
Many applications require configuration via some combination of config files, command line arguments, and environment variables. These configuration artifacts should be decoupled from image content in order to keep containerized applications portable. The ConfigMap API resource provides mechanisms to inject containers with configuration data while keeping containers agnostic of Kubernetes. ConfigMap can be used to store fine-grained information like individual properties or coarse-grained information like entire config files or JSON blobs.
Enter ConfigMaps.
The ConfigMap API resource holds key-value pairs of configuration data that can be consumed in pods or used to store configuration data for system components such as controllers. ConfigMap is similar to Secrets, but designed to more conveniently support working with strings that do not contain sensitive information.
Note: ConfigMaps are not intended to act as a replacement for a properties file. ConfigMaps are intended to act as a reference to multiple properties files. You can think of them as way to represent something similar to the /etc directory, and the files within, on a Linux computer. One example of this model is creating Kubernetes Volumes from ConfigMaps, where each data item in the ConfigMap becomes a new file.
You can use the “kubectl create configmap” command to create configmaps easily from literal values, files, or directories.
API Kubernetes YAML Configurations
APIs are defined to Kubernetes as a deployment YAML file describing how an API is deployed into Kubernetes, coupled to a service YAML file which describes how an API’s port(s) are exposed within and outside of the Kubernetes cluster.
Kubernetes Environments
Kubernetes is quite popular and will run on a variety of platforms:
- Minikube: This is a local instance of Kubernetes that runs on laptops and local machines
- Google Cloud: Google Container Engine is a “Container as a Service” (CaaS) capability which runs Kubernetes on Google’s Cloud Platform
- Amazon AWS: While Amazon AWS does not yet provide native support for Kubernetes in a CaaS offering, there are several tutorials about how to spin up a Kubernetes cluster on Amazon AWS
- Microsoft Azure: Microsoft has a CaaS offering which supports Kubernetes on the Azure platform
- IBM BlueMix: IBM has recently announced support for Kubernetes CaaS on its BlueMix cloud offering
In the following blog post I am going to demonstrate how start a Kubernetes cluster locally on your host machine and visualize the deployment!
References: