
How we almost came in first place at a Google Hackathon
It was a regular afternoon when we received an email from Google. The email was inviting us to participate in a hackathon hosted by Google Cloud Platform. The theme was “Smart Analytics”. The whole team instantly was beyond excited. We have been using Google Cloud Platform at Telus for a few years and we all breathed and lived data. We started to brainstorm on what we could build.

Steve Choi, our team captain suggested we build an explainability model.
Now, before we deep dive into what is an explainability model and Steve's incredible brain let us take a step back and talk about machine learning models.
When a data scientist builds a model they usually follow this pattern:
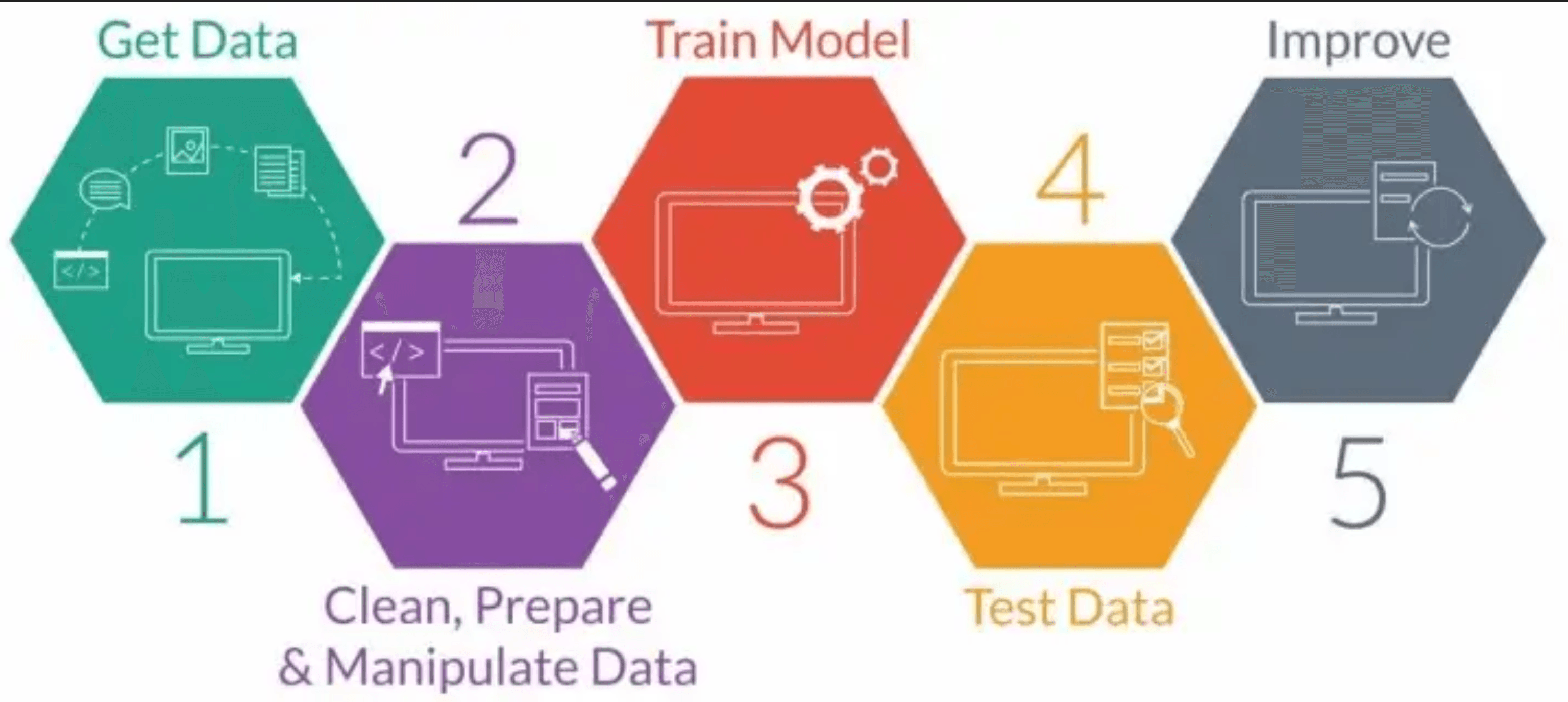
Many data scientists use algorithms like neural networks to make predictions, however neural nets can be hard to comprehend as such they are usually treated as a black box. We cannot understand precisely what feature influenced the model and this is where the concept of explainability comes in.
Explainability promises to shed light into this black box.
The concept is interesting. When we train a model there are different features that weigh into the model's decision. With explainability we can understand the weighting that each feature had into the model's decision hence understanding the why apart from the how of a prediction.
A real-case example:
Company Acme builds a loan application powered by a machine learning model. The loan application allows customers to submit their personal information such as race, age, income, etc and the application automatically pre-approves them based on the response from the machine learning model.
How can explainability help in this case?
“The eye sees only what the mind is prepared to comprehend.” — Robertson Davies, Tempest-Tost
When developing a model, one of the hardest things for a Data Scientist to do is to be unbiased, since being biased is quite natural and most of us do not even realize when we have a bias. Explainability allows us to highlight inherent biases in our model, by understanding the features that influenced the decision.
Back to our use case, with an explainability model on our loan application we are able to understand why a person was rejected and if it was the result of a bias in the model and simply they did not qualify for financial reasons.
The Hackathon
Once the idea was agreed on the amazing team was created.

From left to right: Nathan Bugden, Jas Lamba, Ajay Ayal, Ozan Coskun, Steve Choi, Gonzalo Vazquez, Attiq Ahmed and Fernando Alfaro.
After 48 hours of continuous coding and an endless supply of energy drinks our project was completed. We built an explainability model in a data pipeline. The pipeline was divided into four sections, data ingestion, machine learning, data transformation and explainability. Each sectioned utilized different GCP services to enable us to render an explainability based on the model supplied.
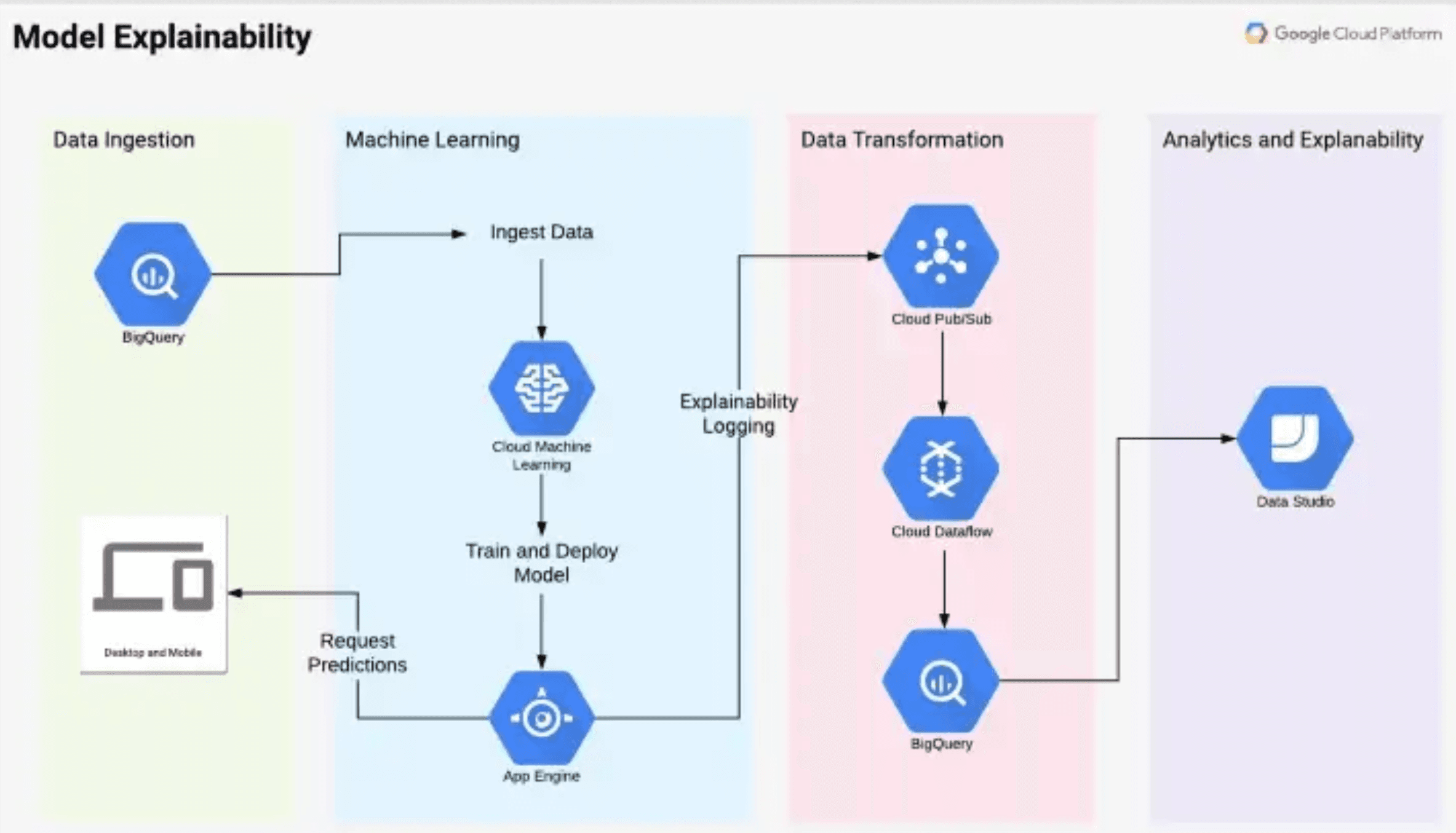
Steve, in the following blog post explains the data platform and our solution in detail.
The Presentation
The presentation was different than most hackathons I have attended. Rather than having one presentation to a broader audience, we had three judges come around our table and listen to our pitches. Each judge would then grade us and submit their recommendation to advance to the final round.

After the three presentations, the nerve-racking wait started for Google to announce which team would move to the final round. As you may have guessed by the title, we advanced to the final round!

The Final Product
After hearing the interesting pitches from the other finalists, the judges made their decision and we learned that we had come in second place. While we were hoping to finish first, the hackathon was a great learning opportunity. It also taught me that it is not the team with the best idea that wins but the one with the most viable idea to take to market. I look forward to attending more hackathons!
Thank you Google and Hackworks for a great couple of days.
